

MARKETING 101 :: A restaurant in Malaysia has a discount system depending on how thin you are ….
FINTECH: LinkedIn Power Profile for 2015 (Finance) and LinkedIn Power Profile for 2017 (Technology) #Equality #DiversitynInclusion #Resilience #TEDTalks #LeanIn #Speaker





– Don’t ever attach yourself to a person, a place, a company, an organisation or a project.
– Attach yourself to a mission, a calling, or a purpose ONLY.
That’s how you keep your power & your peace. It has worked pretty well for me thus far.












A “team” is not just people who work at the same time in the same place. A real team is a group of very different individuals who enjoy working together and who share a commitment to working cohesively to help the organization achieve their common goals and to fulfill its purpose.
Being a part of a team and feeling support from your teammates is one of the best feelings one can have at work. There’s power in a group of people who work together toward a shared goal. This is what true support is all about. Supported teams are successful teams. Leaders are only as successful as their teams, and the great ones know that with the right team dynamics, decisions, and diverse personalities, everyone wins.
#leadershipfirst #leadership #giffordthomas #executivesandmanagement #management #entrepeneurship #womenleadership #inspirationalwomen #leadershipfirstquotes


They say failure is opposite of success…..
I say failure is a part of success![]() ..
..
.
.
They say failure is a lesson learned…..
I say success is all about application of lesson learnt![]() ..
..
.
.
They say failure is absence of success
I say not being successful is absence of trying![]() ..
..
.
.
They say that they feel bad bcoz I am different…..
And I say ,I feel pity on then bcoz you all are same![]() ..
..
.
.
![]() CRUX
CRUX![]()
Be different & be YOURSELF.


22,000 CRORE OF ECOMMERCE SALES IN FIRST 4 DAYS! #Ecommerce firms Flipkart Amazon Myntra and Snapdeal together sold goods worth 22,000CR in the first 4 days of the first festival season sale event which kicked off last week, according to Red Seer The growth this year can be attributed to pent-up demand who have not really shopped over the past few months of the pandemic and newer customers coming from tier 2 and 3 markets. For Amazon, 91% of its new customer base came from Tier 2 cities while for Flipkart it’s 65% #Smartphones continue to hold poll position with its share expected to cross 45% of overall online GMV. Indicative data shows that electronics has also done well and #online grocery with the heavy offers. With Flipkart planning other smaller sale events in the coming weeks and Amazon continuing its month-long ‘Great Indian Festival’ sale the #ecommerce firms might top $4 billion in GMV. These are signs of a come back and it’s sure seems the festival has brought it all back, and with that a money spin to roll out for new #jobs many more opportunities and a boost for the overall economy too.

There is usually constant evolution and the STS alone had different versions of cockpit starting from 77-81/STS-1 with CRTs till JSC2000-E-10522 (March 2000) glass cockpit but still with physical buttons which I like far better than wall of touch screens in current SpaceX dragons





































A radical new technique lets AI learn with practically no data
“Less than one”-shot learning can teach a model to identify more objects than the number of examples it is trained on.
October 16, 2020

hide
Machine learning typically requires tons of examples. To get an AI model to recognize a horse, you need to show it thousands of images of horses. This is what makes the technology computationally expensive—and very different from human learning. A child often needs to see just a few examples of an object, or even only one, before being able to recognize it for life.
In fact, children sometimes don’t need any examples to identify something. Shown photos of a horse and a rhino, and told a unicorn is something in between, they can recognize the mythical creature in a picture book the first time they see it.

Now a new paper from the University of Waterloo in Ontario suggests that AI models should also be able to do this—a process the researchers call “less than one”-shot, or LO-shot, learning. In other words, an AI model should be able to accurately recognize more objects than the number of examples it was trained on. That could be a big deal for a field that has grown increasingly expensive and inaccessible as the data sets used become ever larger.
The researchers first demonstrated this idea while experimenting with the popular computer-vision data set known as MNIST. MNIST, which contains 60,000 training images of handwritten digits from 0 to 9, is often used to test out new ideas in the field.
In a previous paper, MIT researchers had introduced a technique to “distill” giant data sets into tiny ones, and as a proof of concept, they had compressed MNIST down to only 10 images. The images weren’t selected from the original data set but carefully engineered and optimized to contain an equivalent amount of information to the full set. As a result, when trained exclusively on the 10 images, an AI model could achieve nearly the same accuracy as one trained on all MNIST’s images.


The Waterloo researchers wanted to take the distillation process further. If it’s possible to shrink 60,000 images down to 10, why not squeeze them into five? The trick, they realized, was to create images that blend multiple digits together and then feed them into an AI model with hybrid, or “soft,” labels. (Think back to a horse and rhino having partial features of a unicorn.)
“If you think about the digit 3, it kind of also looks like the digit 8 but nothing like the digit 7,” says Ilia Sucholutsky, a PhD student at Waterloo and lead author of the paper. “Soft labels try to capture these shared features. So instead of telling the machine, ‘This image is the digit 3,’ we say, ‘This image is 60% the digit 3, 30% the digit 8, and 10% the digit 0.’”
Once the researchers successfully used soft labels to achieve LO-shot learning on MNIST, they began to wonder how far this idea could actually go. Is there a limit to the number of categories you can teach an AI model to identify from a tiny number of examples?
Surprisingly, the answer seems to be no. With carefully engineered soft labels, even two examples could theoretically encode any number of categories. “With two points, you can separate a thousand classes or 10,000 classes or a million classes,” Sucholutsky says.
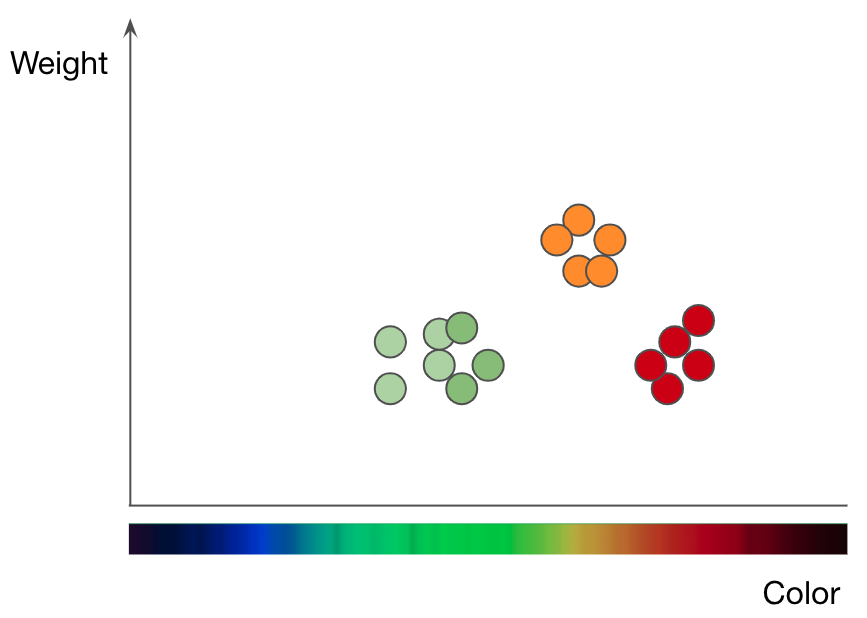
This is what the researchers demonstrate in their latest paper, through a purely mathematical exploration. They play out the concept with one of the simplest machine-learning algorithms, known as k-nearest neighbors (kNN), which classifies objects using a graphical approach.
To understand how kNN works, take the task of classifying fruits as an example. If you want to train a kNN model to understand the difference between apples and oranges, you must first select the features you want to use to represent each fruit. Perhaps you choose color and weight, so for each apple and orange, you feed the kNN one data point with the fruit’s color as its x-value and weight as its y-value. The kNN algorithm then plots all the data points on a 2D chart and draws a boundary line straight down the middle between the apples and the oranges. At this point the plot is split neatly into two classes, and the algorithm can now decide whether new data points represent one or the other based on which side of the line they fall on.
To explore LO-shot learning with the kNN algorithm, the researchers created a series of tiny synthetic data sets and carefully engineered their soft labels. Then they let the kNN plot the boundary lines it was seeing and found it successfully split the plot up into more classes than data points. The researchers also had a high degree of control over where the boundary lines fell. Using various tweaks to the soft labels, they could get the kNN algorithm to draw precise patterns in the shape of flowers.
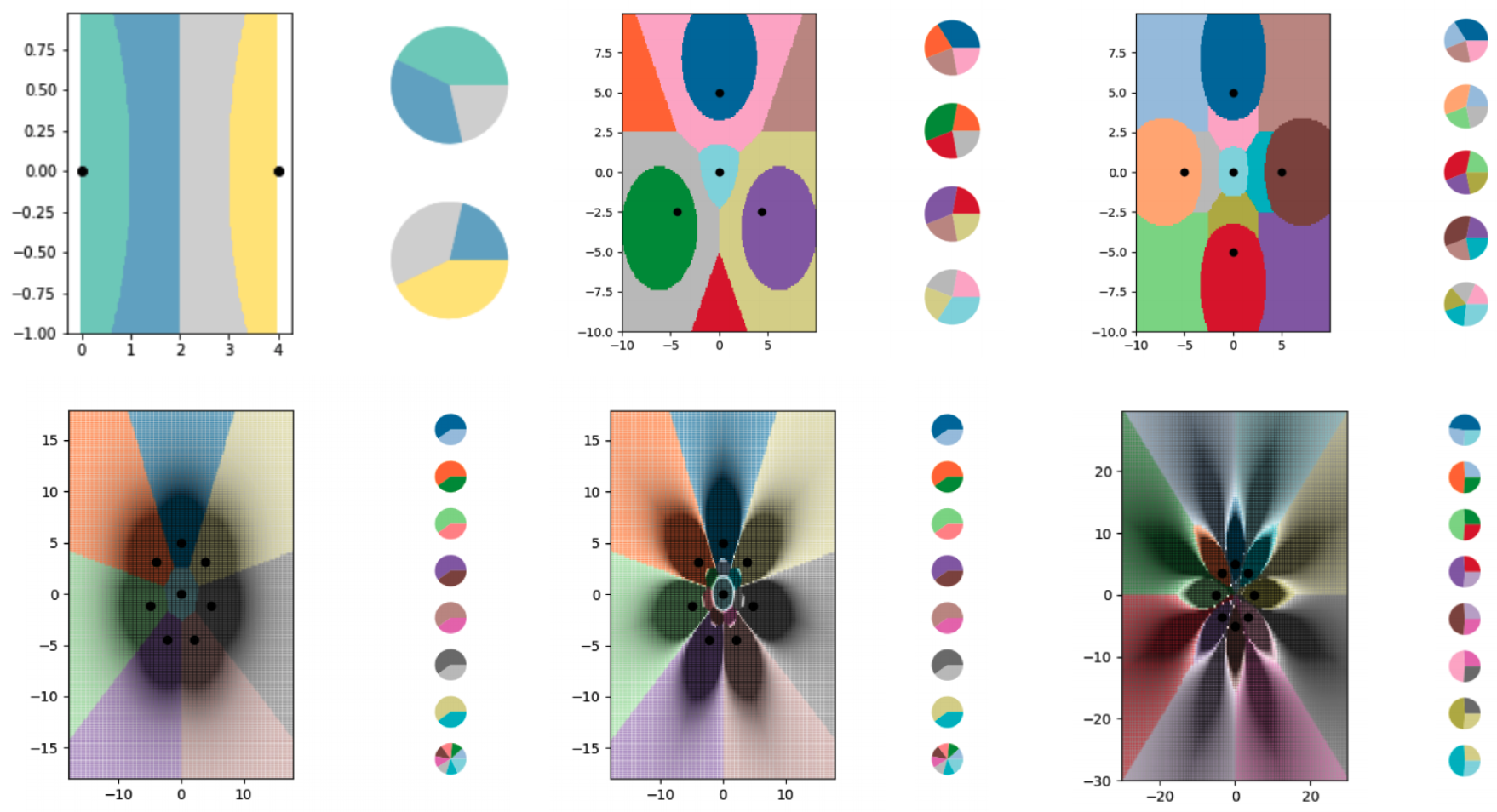
Of course, these theoretical explorations have some limits. While the idea of LO-shot learning should transfer to more complex algorithms, the task of engineering the soft-labeled examples grows substantially harder. The kNN algorithm is interpretable and visual, making it possible for humans to design the labels; neural networks are complicated and impenetrable, meaning the same may not be true. Data distillation, which works for designing soft-labeled examples for neural networks, also has a major disadvantage: it requires you to start with a giant data set in order to shrink it down to something more efficient.
Sucholutsky says he’s now working on figuring out other ways to engineer these tiny synthetic data sets—whether that means designing them by hand or with another algorithm. Despite these additional research challenges, however, the paper provides the theoretical foundations for LO-shot learning. “The conclusion is depending on what kind of data sets you have, you can probably get massive efficiency gains,” he says.
This is what most interests Tongzhou Wang, an MIT PhD student who led the earlier research on data distillation. “The paper builds upon a really novel and important goal: learning powerful models from small data sets,” he says of Sucholutsky’s contribution.
Ryan Khurana, a researcher at the Montreal AI Ethics Institute, echoes this sentiment: “Most significantly, ‘less than one’-shot learning would radically reduce data requirements for getting a functioning model built.” This could make AI more accessible to companies and industries that have thus far been hampered by the field’s data requirements. It could also improve data privacy, because less information would have to be extracted from individuals to train useful models.
Sucholutsky emphasizes that the research is still early, but he is excited. Every time he begins presenting his paper to fellow researchers, their initial reaction is to say that the idea is impossible, he says. When they suddenly realize it isn’t, it opens up a whole new world.


Regina Barzilay, the first winner of the Squirrel AI Award, on why the pandemic should be a wake-up call.by
September 23, 2020 RACHEL WU / MIT CSAILhide
RACHEL WU / MIT CSAILhide
Regina Barzilay, a professor at MIT’s Computer Science and Artificial Intelligence Laboratory (CSAIL), is the first winner of the Squirrel AI Award for Artificial Intelligence for the Benefit of Humanity, a new prize recognizing outstanding research in AI. Barzilay started her career working on natural-language processing. After surviving breast cancer in 2014, she switched her focus to machine-learning algorithms for detecting cancer and designing new drugs. The award will be presented in February 2021 by the Association for the Advancement of Artificial Intelligence (AAAI).
The $1 million prize money, provided by Chinese online education company Squirrel AI, which we have written about previously, puts the award on the same financial level as the Nobel Prize and the Turing Award in computer science. I talked to Barzilay on the phone about the prize—and the promise and frustrations of AI.
Congratulations on this award. What does it mean to you and to AI in general?
Thank you. You know, there are lots of areas where AI still isn’t making a difference but could be. We use machine translation or recommender systems all the time, but nobody thinks of these as fancy technology, nobody asks about them. But with other areas of our life that are crucial to our well-being, such as health care, AI doesn’t yet have the acceptance of society. I hope that this award, and the attention that comes with it, helps to change people’s minds and lets them see the opportunities—and pushes the AI community to take the next steps.
What kinds of steps?
Back when technology moved from steam power to electricity, the first attempts to bring electricity to industry weren’t very successful because people just tried to replicate steam engines. I think something similar is going on now with AI. We need to work out how to integrate it into many different areas: not just health care, but education, materials design, city planning, and so on. Of course, there is more to do on the technology side, including making better algorithms, but we are bringing this technology into highly regulated environments and we have not really looked at how to do that.
Right now AI is flourishing in places where the cost of failure is very low. If Google finds you a wrong translation or gives you a wrong link, it’s fine; you can just go to the next one. But that’s not going to work for a doctor. If you give patients the wrong treatment or miss a diagnosis, there are really serious implications. Many algorithms can actually do things better than humans. But we always trust our own intuitions, our own mind, more than something we don’t understand. We need to give doctors reasons to trust AI. The FDA is looking at this problem, but I think it’s very far from solved in the US, or anywhere else in the world.
In 2014 you were diagnosed with breast cancer. Did that change how you thought about your work?
Oh, yeah, absolutely. One of the things that happened when I went through treatment and spent inordinate amounts of time in the hospital is that the things I’d been working on now felt trivial. I thought: People are suffering. We can do something.
When I started treatment, I would ask what happens to patients like me, with my type of tumor and my age and this treatment. They would say: “Oh, there was this clinical trial, but you don’t really fit it exactly.” And I thought, breast cancer is a very common disease. There are so many patients, with so much accumulated data. How come we’re not using it? But you can’t get this information easily out of the system in US hospitals. It’s there, but it’s in text. And so I started using NLP to access it. I couldn’t imagine any other field where people voluntarily throw away the data that’s available. But that’s what was going on in medicine.
Did hospitals jump at the chance to make more use of this data?
It took some time to find a doctor who’d work with me. I was telling people, if you have any problem, I will try to solve it. I don’t need funding. Just give me a problem and the data. But it took me a while to find collaborators. You know, I wasn’t a particularly popular character.
From this NLP work I then moved into predicting patient risk from mammograms, using image recognition to predict if you would get cancer or not—how your disease is likely to progress.
Would these tools have made a difference if they had been available to you when you were diagnosed?
Absolutely. We can run this stuff on my mammograms from before my diagnosis, and it was already there—you can clearly detect it. It’s not some kind of miracle—cancer doesn’t grow from yesterday to today. It’s a pretty long process. There are signs in the tissue, but the human eye has limited ability to detect what may be very small patterns. In my case it would have been visible two years before.
Why didn’t the doctor see it?
It’s a hard task. Every mammogram has white spots that may or may not be cancer, and a doctor has to decide which of these white spots needs to be biopsied. The doctor needs to balance acting on intuition versus harming a patient by doing biopsies that aren’t needed. But this is exactly the type of decision that data-driven AI can help us make in a much more systematic way.
Which brings us back to the problem of trust. Do we need a technical fix, making tools more explainable, or do we need to educate the people who use them?
That’s a great question. Some decisions would be really easy to explain to a human. If an AI detects cancer in an image, you can zoom in to the area that the model looks at when it makes the prediction. But if you ask a machine, as we increasingly are, to do things that a human can’t, what exactly is the machine going to show you? It’s like a dog, which can smell much better than us, explaining how it can smell something. We just don’t have that capacity. I think that as the machines become much more advanced, this is the big question. What explanation would convince you if you on your own cannot solve this task?
So should we wait until AI can explain itself fully?
No. Think about how we answer life-and-death questions now. Most medical questions, such as how you will respond to this treatment or that medication, are answered using statistical models that can lead to mistakes. None of them are perfect.
It’s the same with AI. I don’t think it’s good to wait until we develop perfect AI. I don’t think that’s going to happen anytime soon. The question is how to use its strengths and avoid its weaknesses.
Finally, why has AI not yet had much impact on covid-19?
AI is not going to solve all the big problems we have. But there have been some small examples. When all nonessential clinical services were scaled down earlier this year, we used an AI tool to identify which oncology patients in Boston should still go and have their yearly mammogram.
But the main reason AI hasn’t been more useful is not the lack of technology but the lack of data. You know, I’m on the leadership team of MIT’s J-Clinic, a center for AI in health care, and there were lots of us in April saying: We really want to do something—where can we get the data? But we couldn’t get it. It was impossible. Even now, six months later, it’s not obvious how we get data.
The second reason is that we weren’t ready. Even in normal circumstances, when people are not under stress, it is difficult to adopt AI tools into a process and make sure it’s all properly regulated. In the current crisis, we simply don’t have that capacity.
You know, I understand why doctors are conservative: people’s lives are on the line. But I do hope that this will be a wake-up call to how unprepared we are to react fast to new threats. As much as I think that AI is the technology of the future, unless we figure out how to trust it, we will not see it moving forward.








First computer mouse. The first real mouse was invented in 1964 at Stanford University. Then it was in wood with a lone button on top. Today’s mice can be moved in any direction but the first mouse was far from as smooth.








..")


")










You must be logged in to post a comment.